

Step 1. 인트로
안녕하세요 Jarvis입니다. 오늘은 Jarvinspire의 첫 프리미엄 포스팅을 올려 보려고 합니다.
스타트업에서 일하다 보면 유난히 자주 마주치는 키워드가 ‘커뮤니케이션’입니다. ‘수평적 커뮤니케이션’, ‘열린 의사소통’, ‘솔직한 피드백’ 등 나타나는 형태는 매우 다양하지만 정말 많이 사용하는 것 같아요. 기업문화에서 강조하지 않더라도 인터뷰를 진행하다보면 회사에 지원하는 지원자 분들도 강점으로 커뮤니케이션을 꼽는 경우가 아주 많습니다.


그런데 많은 스타트업에서 커뮤니케이션을 강조하고 있는데, 실제로 조직에서 커뮤니케이션이 얼마나 ‘잘’ 이루어지고 있을까요? ‘잘’의 정의는 회사마다 물론 다르겠지만 적어도 ‘잘’이라는 단어가 내포하는 의미에는 ‘비교 가능한’, ‘특정 수준을 이상을 만족하는’ 등의 의미가 포함되어 있다고 생각하고, 결국 ‘분석할 수 있는’까지도 이어지는 것 같습니다. 우리나라에서는 아직 보편화되지는 않았지만 사람의 행동, 관계, 특성과 관련된 데이터를 사업적 결정을 내리는데 사용하는 ‘피플 애널리틱스’의 영역에 포함된다고 할 수 있겠습니다. 오늘은 그 중에서도 네트워크 분석을 통한 조직 커뮤니케이션 진단 방법론에 대해 실제 데이터를 가지고 이야기해보려고 합니다.
사실 조직 커뮤니케이션 진단에 네트워크 분석을 사용해보겠다는 생각은 제가 생각해 낸 아이디어는 아니고, 제가 CUPIST 재직 당시 CEO인 제논의 의견이었습니다. 지금 생각해도 큐피스트는 조직 규모에 비해 HR에 상당한 투자를 하는 회사였는데요, 그 때 당시를 생각해보면 이렇게 이야기가 나왔던 것 같습니다.
자비스,
큐피스트 핵심가치와 관련해서는 나름 데이터를 쌓고 있는 것 같은데 조직 커뮤니케이션에 대해서는 분석해 볼 방법이 없을까요? 대략 이런 네트워크 분석 방법론을 써보면 될 것 같은데요…? (후략)
음...? 이 말이 시작이 되어 네트워크 분석 방법론을 적용해서 어떻게 분석해낼지 고민한 것이 이번 포스팅의 소재가 되었네요(감사합니다, 제논🙂). 저는 통계학 전공이 아니기 때문에 해당 분석이 통계적 측면에서 유의미한지에 대해서까지는 다루지 않습니다만, 실제로 유의미한 내용들을 발굴해 내었다는 것을 알리며 본격적으로 소개해 보겠습니다.
Step2. 분석 툴과 Raw Data 준비하기
이번 분석에서 사용할 툴은 (주)사이람의 넷마이너입니다. 넷마이너는 2001년에 출시된 세계 최초의 상용 SNA(Social Network Analysis) 전문 소프트웨어인데요, 저도 처음 사용해 봤지만 매뉴얼이 잘 갖추어져 있어 어렵지 않게 사용할 수 있었습니다. 넷마이너는 회원가입만 하면 무려 28일 동안 평가판을 사용해 볼 수 있습니다. 만약 이후로도 사용하시려면 구매하시면 되는데 비용은 조금 비쌉니다(자세한 비용은 견적을 받아보셔야 알 수 있습니다). 저는 평가판으로만 진행했지만, 만약 조직 구성원이 100명이 넘고 커뮤니케이션 분석을 정기적으로 하신다고 한다면 정식 버전 구매도 추천합니다.

다음은 Raw Data를 준비하는 단계입니다. 저는 보통 분석을 수행할 때 가설을 세우고 분석을 통해 검증하는 방법을 주로 사용하지만, 이번에는 가설을 세우지 않고 커뮤니케이션의 분야만 선정하였습니다.
- 구성원 간 Relationship
- 팀 내부 Communication
- 팀 외부 Communication
- Feedback
다음은 선정된 각 주제에 대해 질문을 구체화 해 보았습니다.
- 구성원 간 Relationship
- 회사에서 가장 친한 구성원은 누구인가요?
- 내가 힘들 때 회사에서 터 놓고 이야기할 수 있는 구성원은 누구인가요?
- 회사에서 나에게 가장 많은 도움을 주는 구성원은 누구인가요?
- 팀 내부 Communication
- [그룹 혹은 팀]에서 내가 업무적 커뮤니케이션을 가장 많이 하는 구성원은 누구인가요?
- [그룹 혹은 팀]에서 내가 모르는 것이 있을 때 가장 많이 물어보는 구성원은 누구인가요?
- 팀 외부 Communication
- [타 그룹]에서 내가 업무적 커뮤니케이션을 가장 많이 하는 구성원은 누구인가요?
- Feedback
- 나에게 가장 많은 피드백을 하는 구성원은 누구인가요?
- 반대로 내가 가장 많은 피드백을 하는 구성원은 누구인가요?
다음으로 위 8개의 질문에 대해, 최대 3명의 구성원을 선택하게 하는 Google 설문지를 만들어서 구성원들에게 설문을 받은 결과는 아래와 같습니다.
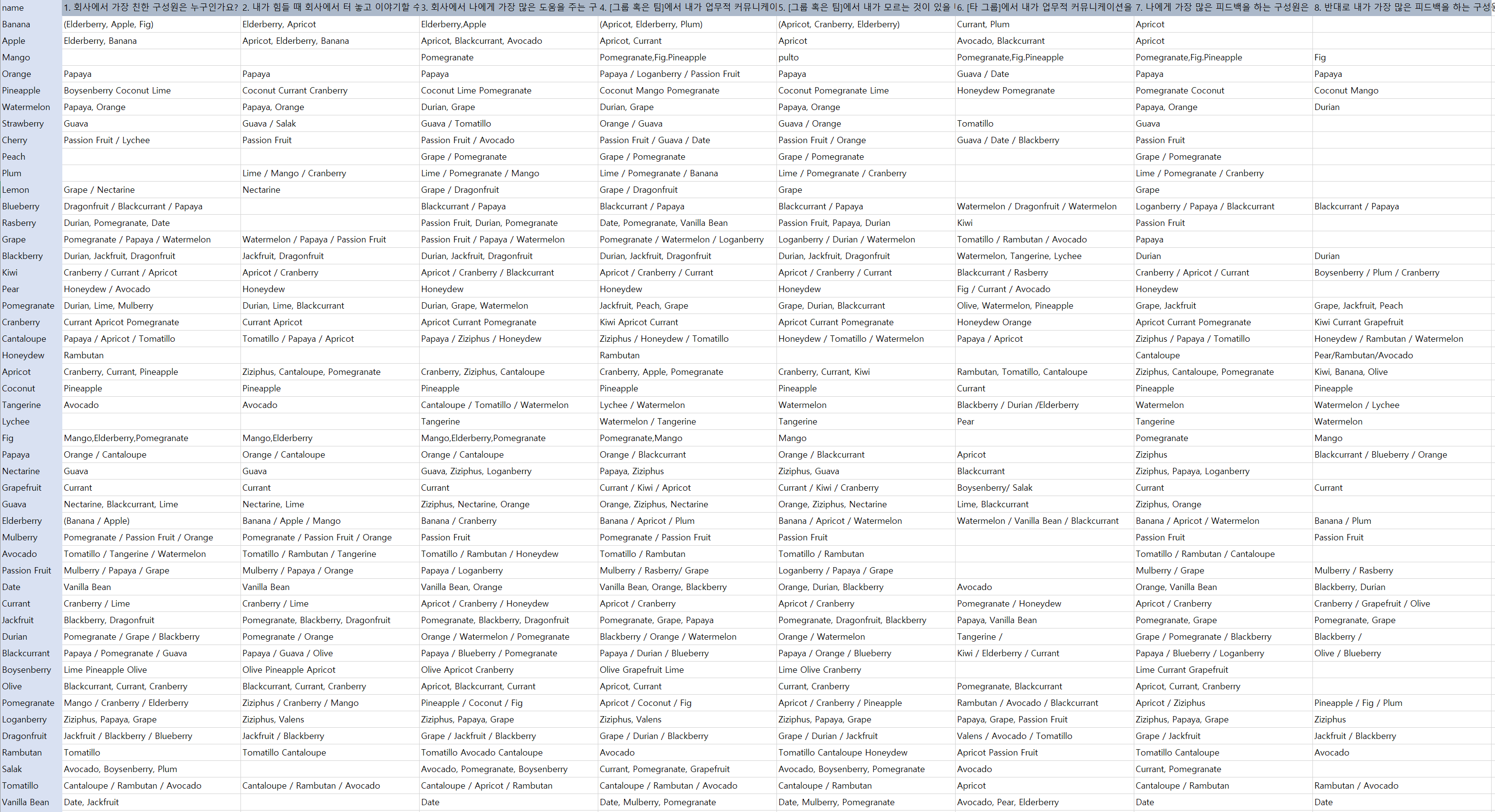
Step 3. Data 가공하기
이렇게 받은 데이터를 넷마이너에 업로드하기 위해 가공해야 하는데요, 우선 가공 과정을 담은 엑셀 파일을 첨부합니다.
엑셀 파일은 총 15개의 sheet로 구성되어 있고, 하나씩 설명드리겠습니다.
- information : 구성원의 기본 정보를 담은 시트입니다. 각 열의 값은 네트워크 분석에서 필터 값으로 사용하거나 노드(점, 여기서는 각 구성원)의 속성을 나타내는 정보로 사용합니다.
- raw : 설문으로 받은 기초자료입니다.
- relationship_1 : 첫 번째 질문에 대해 가공한 시트입니다.
- 가령, raw sheet의 B2 table에는 Elderberry, Apple, Fig라는 데이터가 들어가 있는데 이 데이터를 relationship_1 sheet의 B2, B3, B4로 쪼갠 형태입니다.
- relationship_2 : 두 번째 질문에 대해 가공한 시트입니다.
- relationship_3 : 세 번째 질문에 대해 가공한 시트입니다.
- 팀 내부 커뮤니케이션_1 : 네 번째 질문에 대해 가공한 시트입니다.
- 팀 내부 커뮤니케이션_1 : 다섯 번째 질문에 대해 가공한 시트입니다.
- 팀 외부 커뮤니케이션_1 : 여섯 번째 질문에 대해 가공한 시트입니다.
- Feedback_1 : 일곱 번째 질문에 대해 가공한 시트입니다.
- Feedback_2 : 여덟 번째 질문에 대해 가공한 시트입니다.
- sum_relationship : 3번 ~ 5번을 합친 시트입니다.
- name 열 : 설문에 응답한 구성원의 이름입니다.
- relationship 열 : 3번 ~ 5번에서 name열의 구성원이 선택한 구성원입니다.
- weight 열 : 가중치 열입니다. sum_relationship의 C5에 3이라고 표기되었다는 것은 Banana가 Elderberry를 3번, 4번, 5번 질문에서 모두 선택했다는 의미입니다.
- sum_팀 내부 커뮤니케이션 : 6번, 7번을 합친 시트입니다. 열 값의 설명은 11번과 동일합니다.
- sum_팀 외부 커뮤니케이션 : 8번과 동일하고, weight 열이 모두 1로 들어가 있습니다.
- sum_Feedback : 9번, 10번을 합친 시트입니다. 열 값의 설명은 11번과 동일합니다.
- hierarchy : 구성원 간 하이어라키를 표기하는 시트입니다.
- name 열 : 조직의 최하단 구성원은 없고, 팀원이 1명이라도 있는 리더만 표기합니다.
- hierarchy 열 : name열의 구성원이 리더인 구성원 이름이 표기됩니다.
- weight 열 : 가중치는 전부 1로 기재하였습니다.
- 해당 시트는 분석의 기초로서, 가령 동일한 형태에서 조직도와 피드백 네트워크가 어떻게 다른지 등의 분석을 가능하게 하는 시트입니다.
이렇게 해서 넷마이너에 올릴 Dataset이 완성되었습니다. 아래는 이 단계에서 궁금하실 만한 FAQ를 기재했습니다.
15개의 sheet에서 실제로 분석에 쓰이는 sheet는 1, 11, 12, 13, 14, 15번이기 때문에 다른 시트는 삭제하시고 사용하셔도 무방합니다. 실제로 넷마이너에 엑셀 파일을 업로드할 때는 저 6개의 시트 빼고는 삭제하고 업로드합니다.
각 구성원 간 Network 연결의 강도를 측정하기 위해 필요합니다(실제 넷마이너에서는 선의 굵기로 표현할 수 있습니다). 이번 Dataset에서는 relationship의 강도를 측정하는 설계가 포함되어 있기 때문에 weight가 다릅니다만, 단순 연결만 보려면 weight를 1로 만드는 설계도 가능합니다.
아닙니다, 넷마이너에서는 크게 3가지의 형태를 insert할 수 있는데 Edge LIst, Matrix, Linked List를 제공합니다. 어떤 형태든 업로드하면 분석에 필요한 형태로 넷마이너가 다시 가공합니다.
Step 4. 넷마이너에 데이터 올리기
- 우선 회원가입을 하신 후, 넷마이너 평가판을 설치해 주세요. 그리고 나서 넷마이너를 실행하시면 아래의 화면이 출력됩니다.
- 샘플 엑셀 파일에서 1, 11 ~ 15번 시트를 제외한 나머지 시트를 삭제하고 저장합니다.
- 상단의 File → Import → Excel File을 클릭합니다.
- 팝업 창에서 Browse를 클릭해서 엑셀 파일을 찾은 후 확인을 누르면 아래와 같이 됩니다
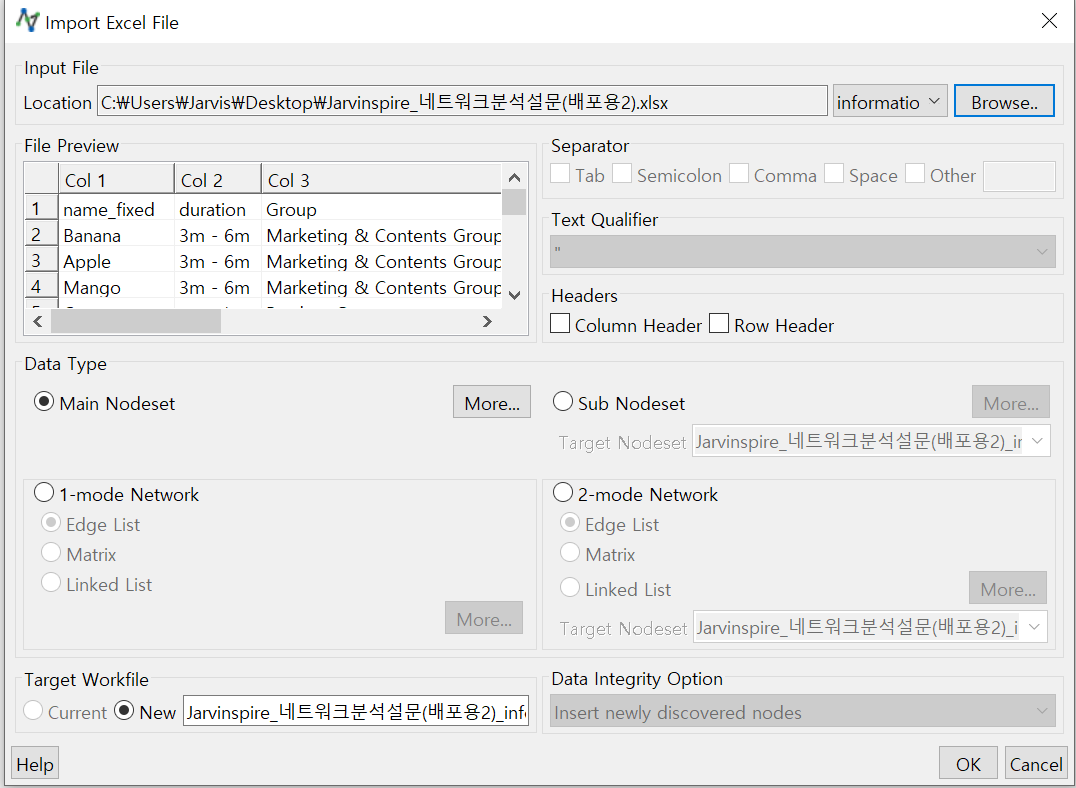
- Browse 버튼 옆에 드롭다운 메뉴로 엑셀파일의 각 시트가 들어가 있습니다. 지금은 information 시트가 선택되어 있고요. File Preview에서 첫 번째 행(name_fixed, duration, group)을 선택하신 후 오른쪽 Headers에서 Column Header를 클릭하면 아래와 같이 File Preview가 바뀝니다.
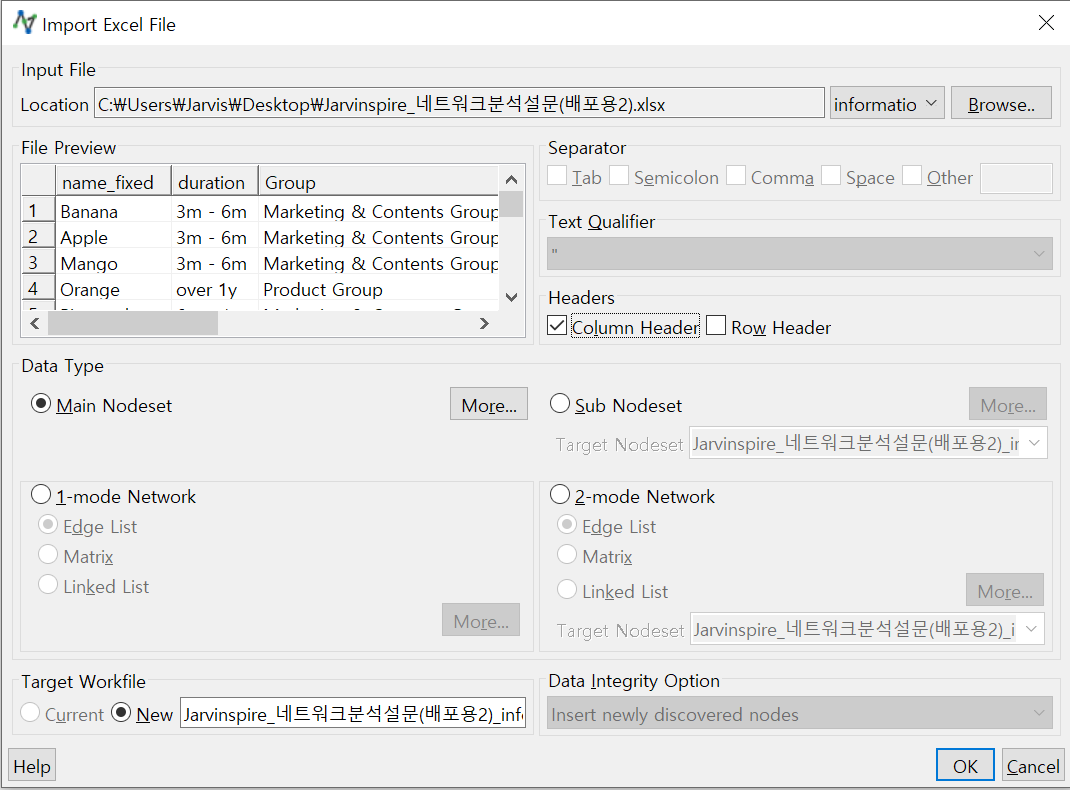
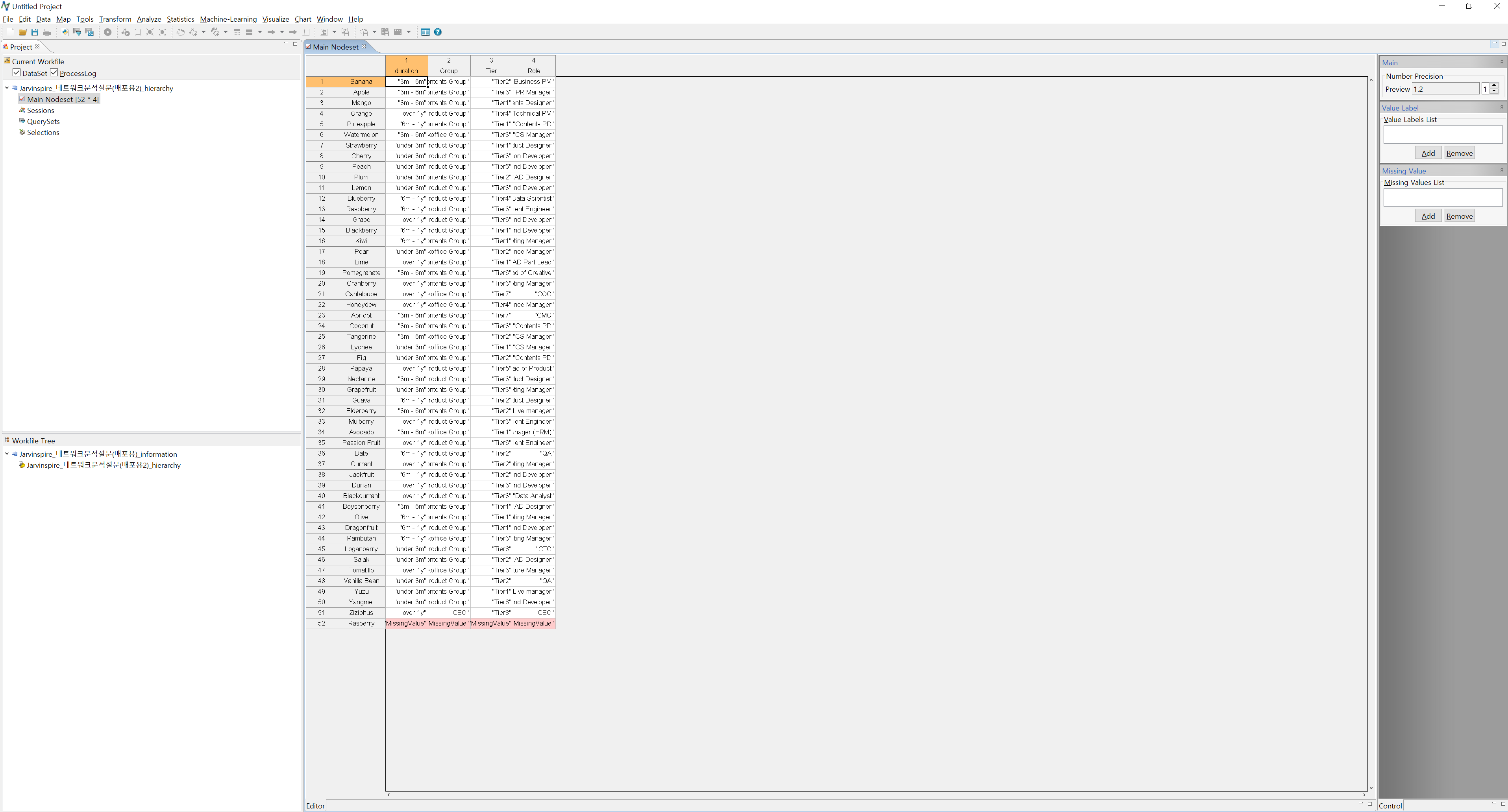
- 아래 Data Type은 크게 Main Nodeset, Sub Nodeset, 1-mode Network, 2-mode Network가 있는데 information 시트는 Main Nodeset의 역할을 합니다. Main Nodeset을 체크한 후 OK를 누르면 아래와 같이 데이터가 insert됩니다.
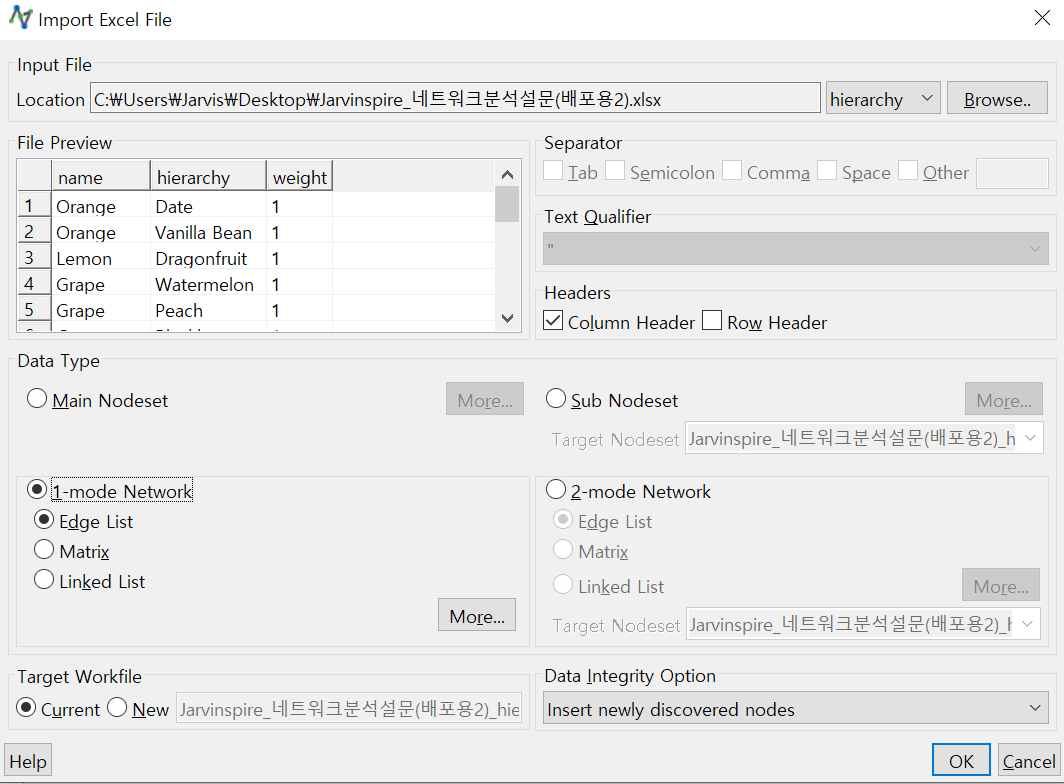
- 상단의 File → Import → Excel File을 클릭한 후 Browse 버튼을 눌러 파일 선택 후, Browse 버튼 옆의 시트 선택에서 hierarchy 시트를 선택합니다. 선택하면 5에서 설명한 Column Header는 자동으로 지정되고요, 지정 안 되어 있으면 5를 반복해서 해 주시면 됩니다. 그리고 Data Type을 1-mode Network의 Edge List로 선택해 줍니다. Edge List로 선택하는 이유는 현재 시트의 형태가 Edge List이기 때문입니다. 그리고 나서 OK를 눌러줍니다.
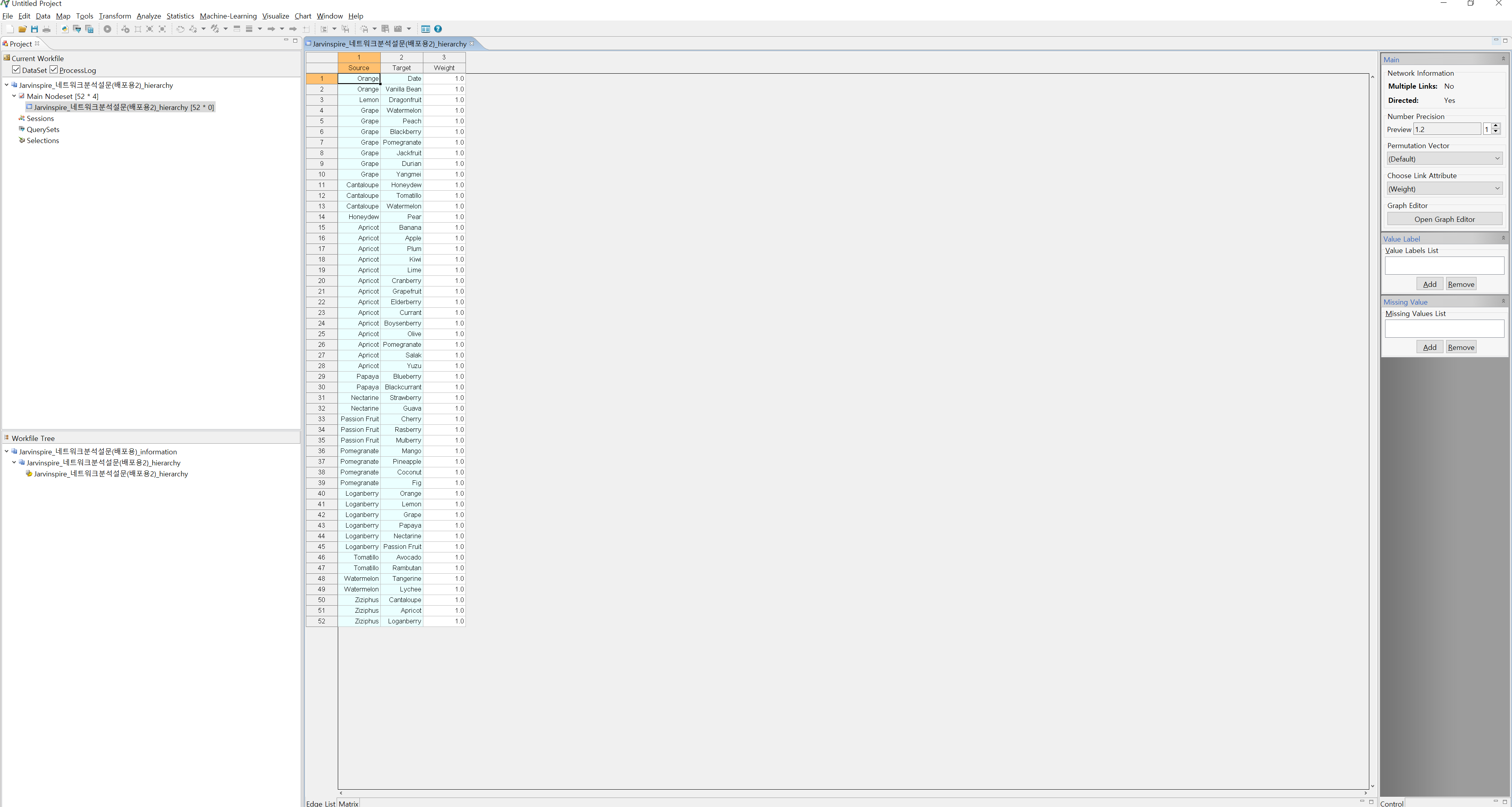
- 다른 모든 시트에 대해서도 7과 동일하게 작업해준 후, OK를 눌러줍니다. 아래와 같은 화면을 보실 수 있습니다(테이블이 안 보이시는 분은 좌측 워크파일 영역에서 파일명_시트명을 클릭하시면 보입니다.
- 다른 모든 시트에 대해서도 7~8의 작업을 반복합니다.
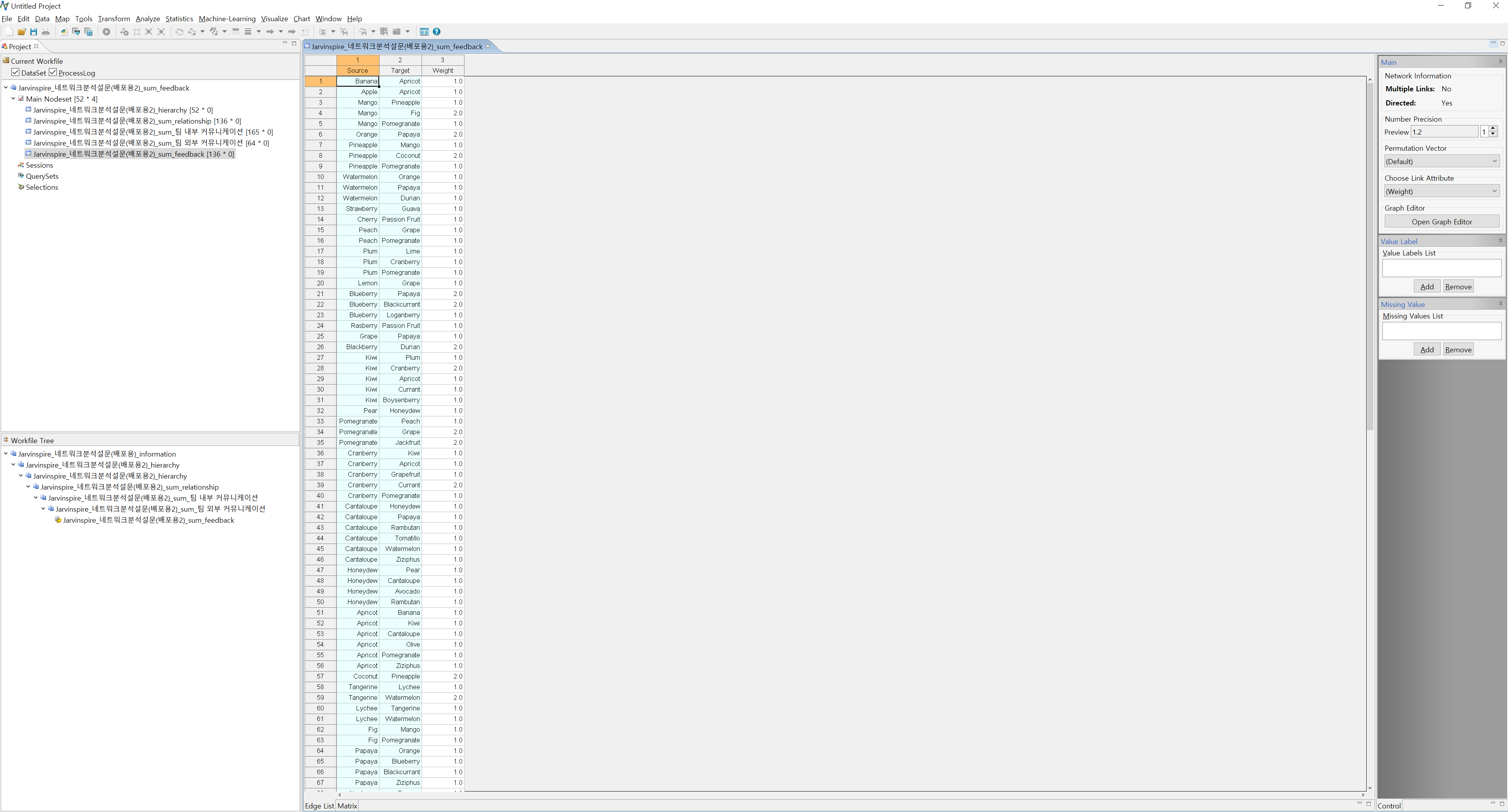
이렇게 해서 넷마이너에 Dataset을 업로드 했습니다. 아래는 이 단계에서 궁금하실 만한 FAQ를 기재했습니다.
Matrix형태로 데이터를 봤을 때 행과 열을 구성하는 노드셋이 동일하면 1-mode network, 다르면 2-mode network 타입이 됩니다. 자세한 설명은 본 포스팅 최하단의 넷마이너 가이드북 문서를 참고하시면 자세하게 설명이 되어 있습니다.
Step 5. 데이터를 시각화하기
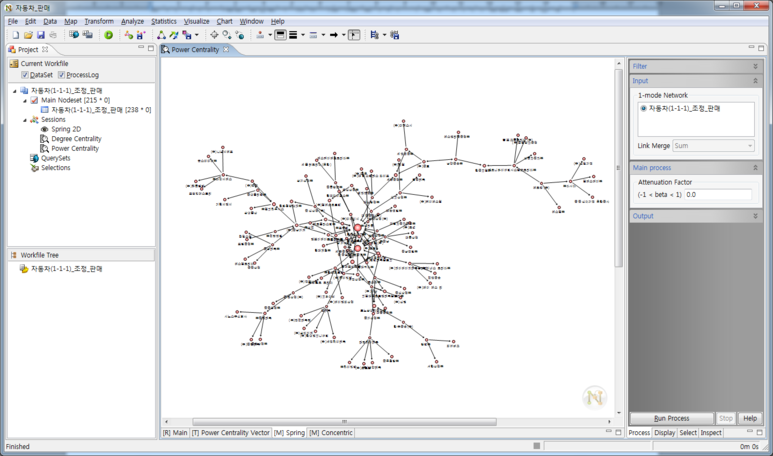
- 넷마이너 왼쪽에서 Jarvinspire_ 네트워크분석(배포용)_hierarchy를 클릭 후, 상단 메뉴에서 Visualize → Spring → 2D를 클릭합니다. 클릭하시면 아래와 같은 화면이 출력됩니다.
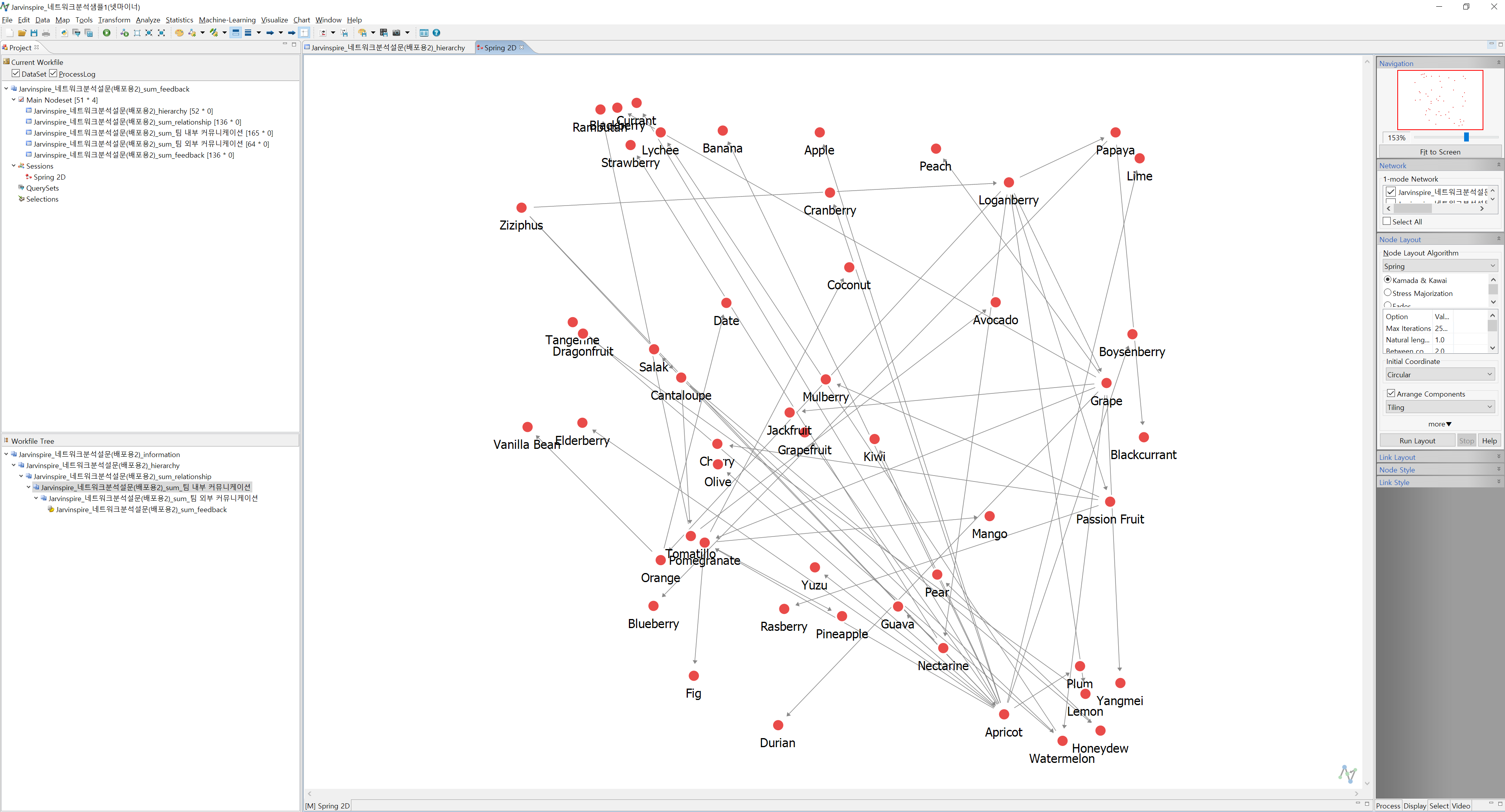
- 오른쪽 작업 메뉴에서 Run Layout을 누르면 아래와 같이 변합니다. 현재는 Node Layout이 Kamada & Kawai로 선택되어 있는데, 다른 것을 선택하시고 Run Layout을 누르면 네트워크 모양이 조금씩 변합니다(모델링의 차이인 듯)
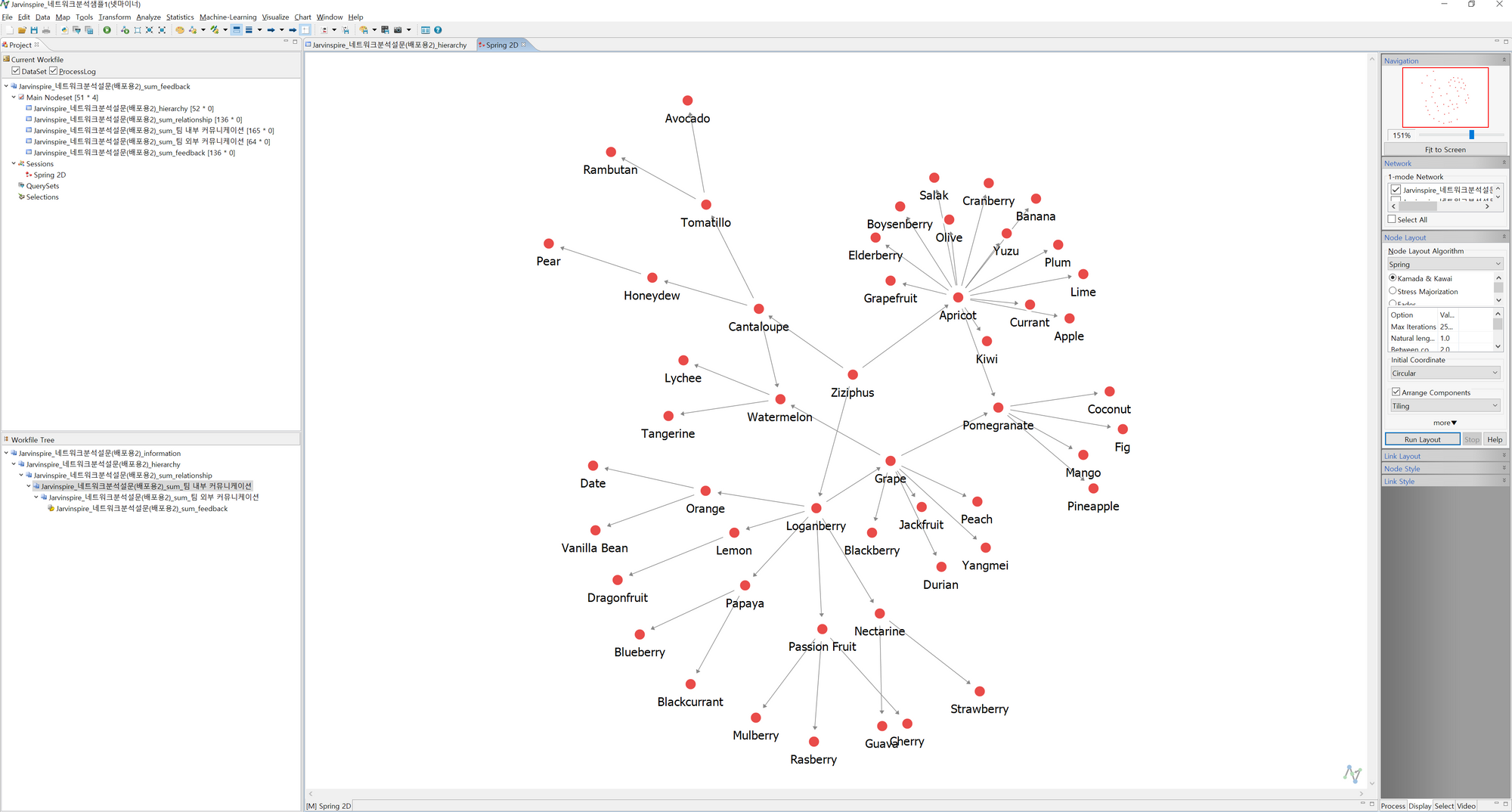
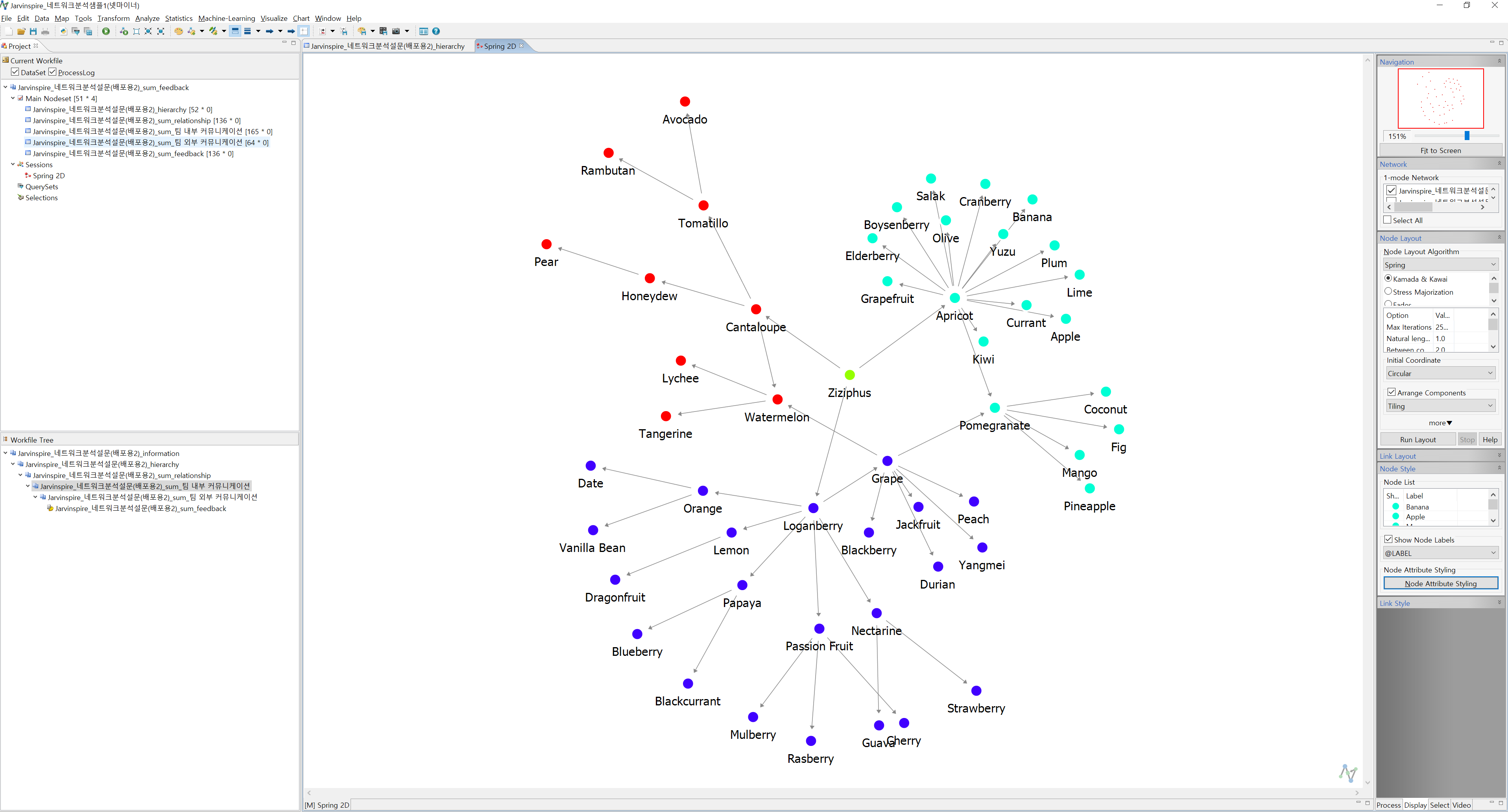
- 오른쪽 작업 메뉴 하단에서 Node Style을 누르고 Node Attribute Styling을 눌러 팝업을 출력합니다. 해당 작업은 각 노드에 속성값(엑셀 시트의 Information에 있는 열 값)을 표기하기 위한 작업입니다. 저는 Color로는 각 구성원의 그룹을, Size로는 각 구성원의 Tier를, Shape으로는 Duration을 표기할 예정입니다. 현재 Color 탭에서 Variable > Node Attribute 하단에서 Duration이 선택되어 있는데, 해당 값을 Group으로 바꿔주겠습니다.
- Apply를 누르면 네트워크가 아래와 같이 변경됩니다.
- 3의 작업을 반복하여, 이번에는 Size 탭에서 Variable을 Tier로 선택한 후 Apply를 누르면 아래와 같이 변경됩니다.
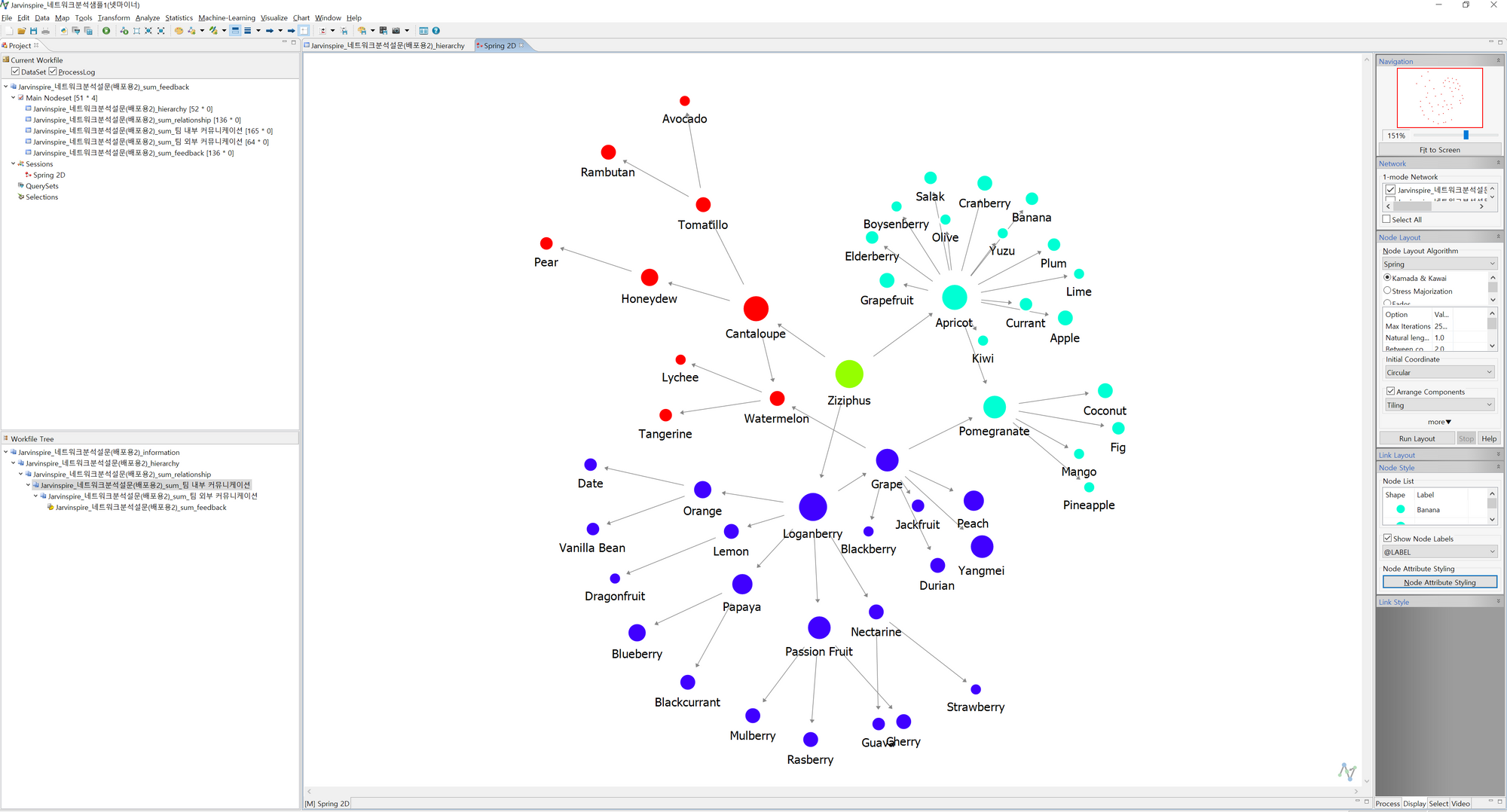
- 3의 작업을 반복하여, 이번에는 Shape 탭에서 Variable을 Duration으로 선택한 후 Apply를 누르면 아래와 같이 변경됩니다.
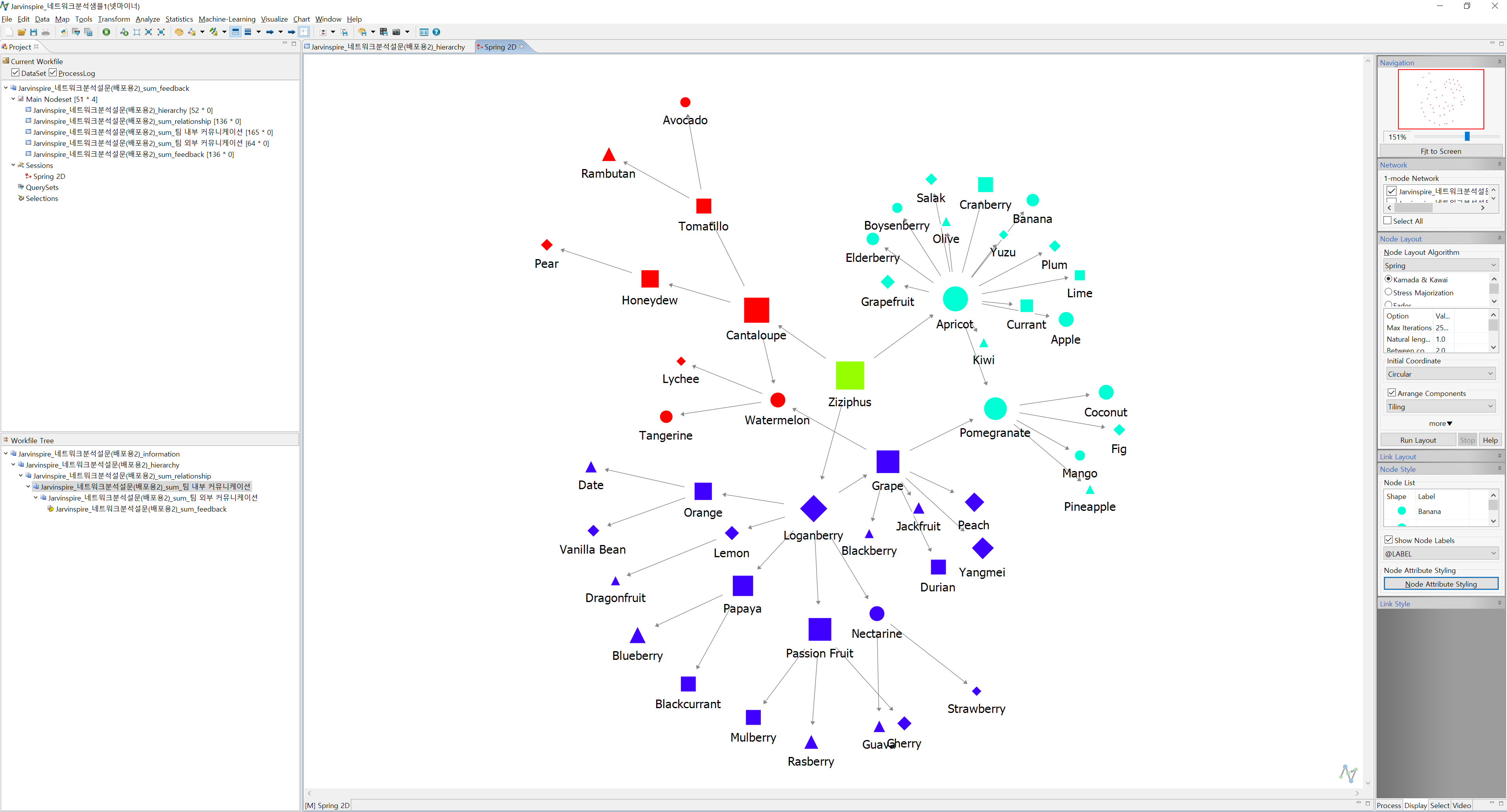
- 이번에는 현재 네트워크 형태를 유지한 채, 하이어라키가 아닌 다른 Data를 적용할 때 네트워크가 어떻게 바뀌는지 살펴보겠습니다. 우측 메뉴 상단 즈음에 Network 라는 메뉴가 있고, 1-mode Network라고 기재되어 있는 부분에 우리가 입력한 여러 시트가 표기되어 있습니다. 여기에서 sum_relationship을 불러오면 아래와 같이 네트워크가 변합니다.
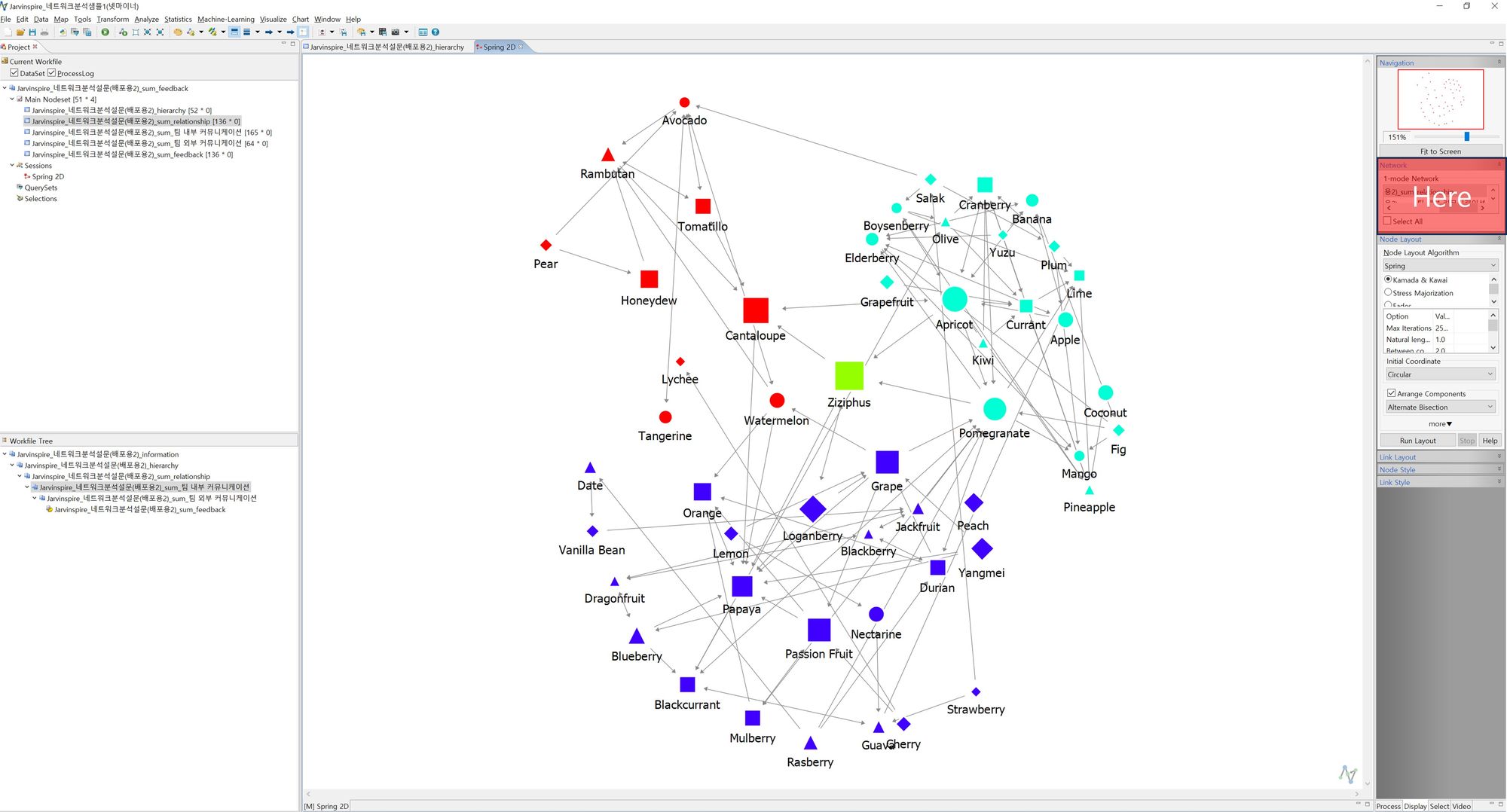
- Relationship의 경우 weight가 1~3까지 분포하므로 이번에는 가중치를 선의 두께로 표현해 보겠습니다. 우측 하단 메뉴에서 Link style → Link Attribute Styling을 눌러 팝업을 출력 후, width 탭을 누릅니다. Variable에서 weight를 선택 후, setting값을 min 1, max 6(꼭 이 값으로 안 하셔도 됩니다)으로 선택 후 Apply를 누르면 네트워크에서 선의 두께가 변한 것을 확인할 수 있습니다.
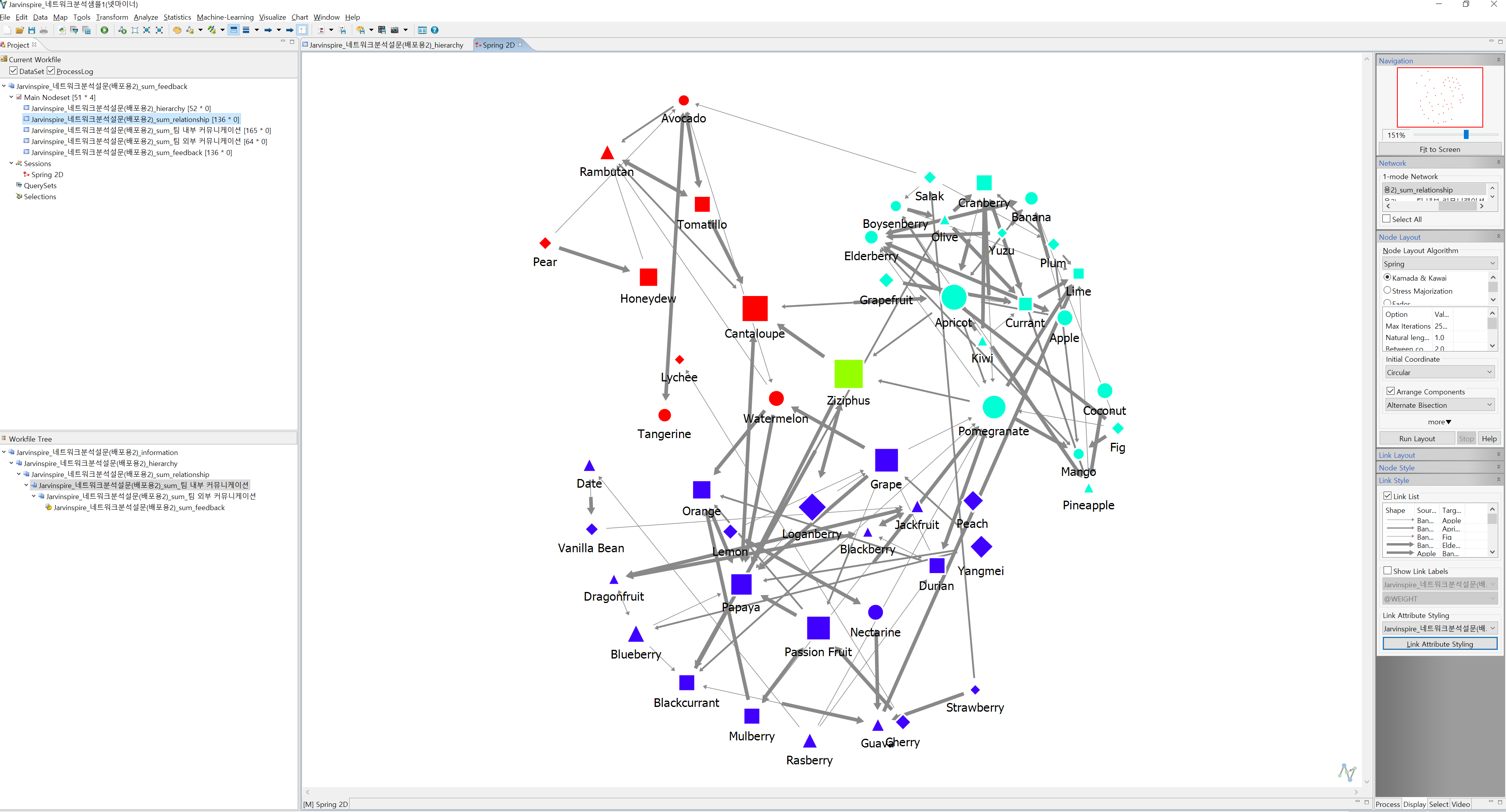
Step 6. 해석 및 문제점 개선하기
Step 5의 7을 반복적으로 돌려보면서 데이터를 수집한 영역에 문제가 있는지 찾아내는 단계입니다. 실제로 여러 문제가 발견되었지만 전부 소개할 수 없어서 케이스 한 가지만 소개하겠습니다.
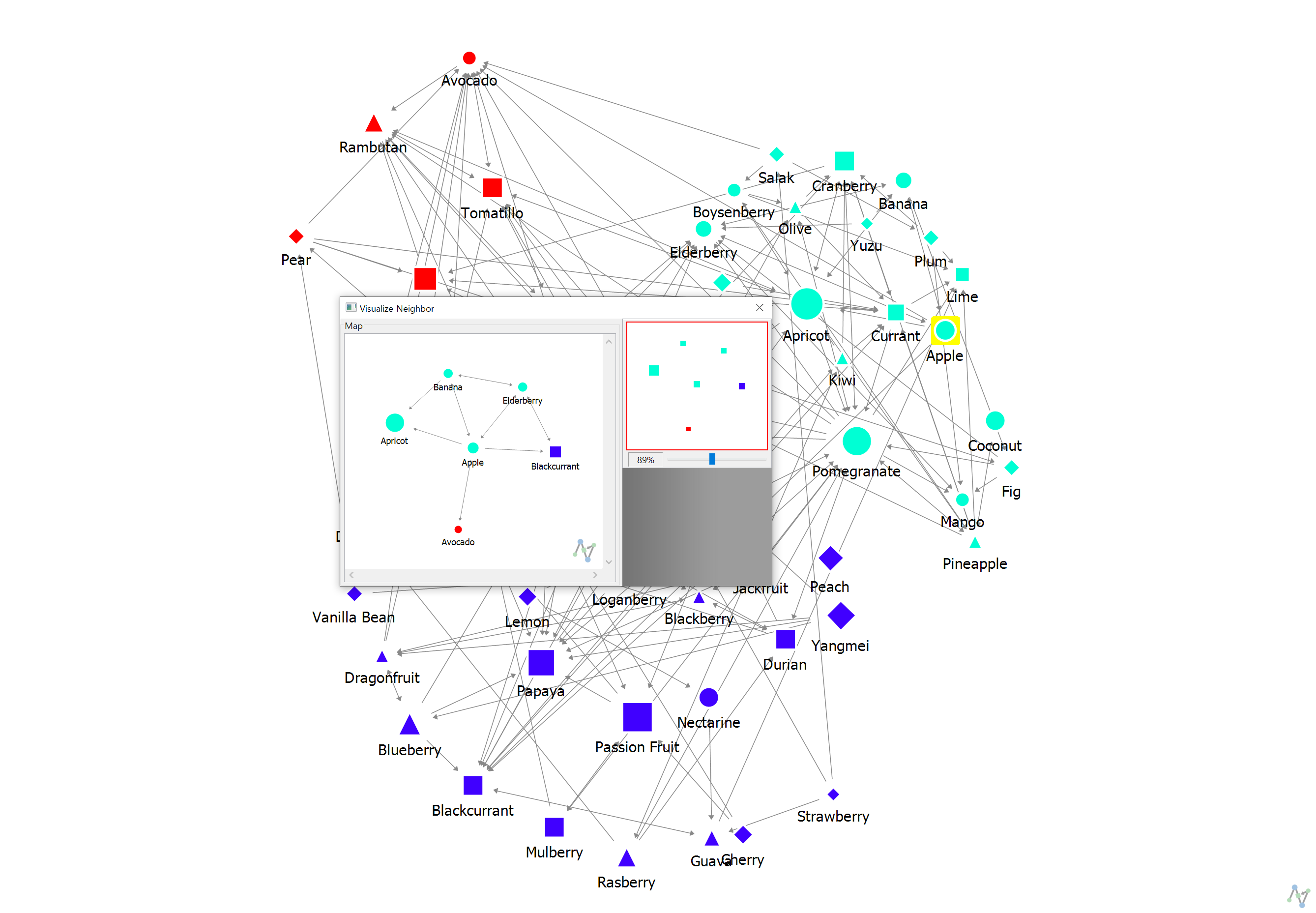
위 케이스는 다른 팀과의 커뮤니케이션에 관련한 네트워크를 도식화한 후, Apple 노드를 우클릭해서 Visualize Neighborhood를 한 결과입니다. 해당 케이스를 보여드리는 이유에 대해 설명드리면 Apple은 회사의 PR Manager입니다. Apple의 Task 중 하나는 외부 PR을 위한 콘텐츠가 있는데, 당시 하나의 아이디어로 내부 구성원을 인터뷰해서 PR 콘텐츠를 만들자는 아이디어가 있었습니다. 그러기 위해서는 Apple이 구성원 소식을 잘 알고 있어야 하는데, 네트워크를 보면 Avocado와 Blackcurrent만 연결되어 있는 것을 알 수 있습니다(최대 3명이기 때문에 한 명이 연결되어 있어야 한다고 생각)
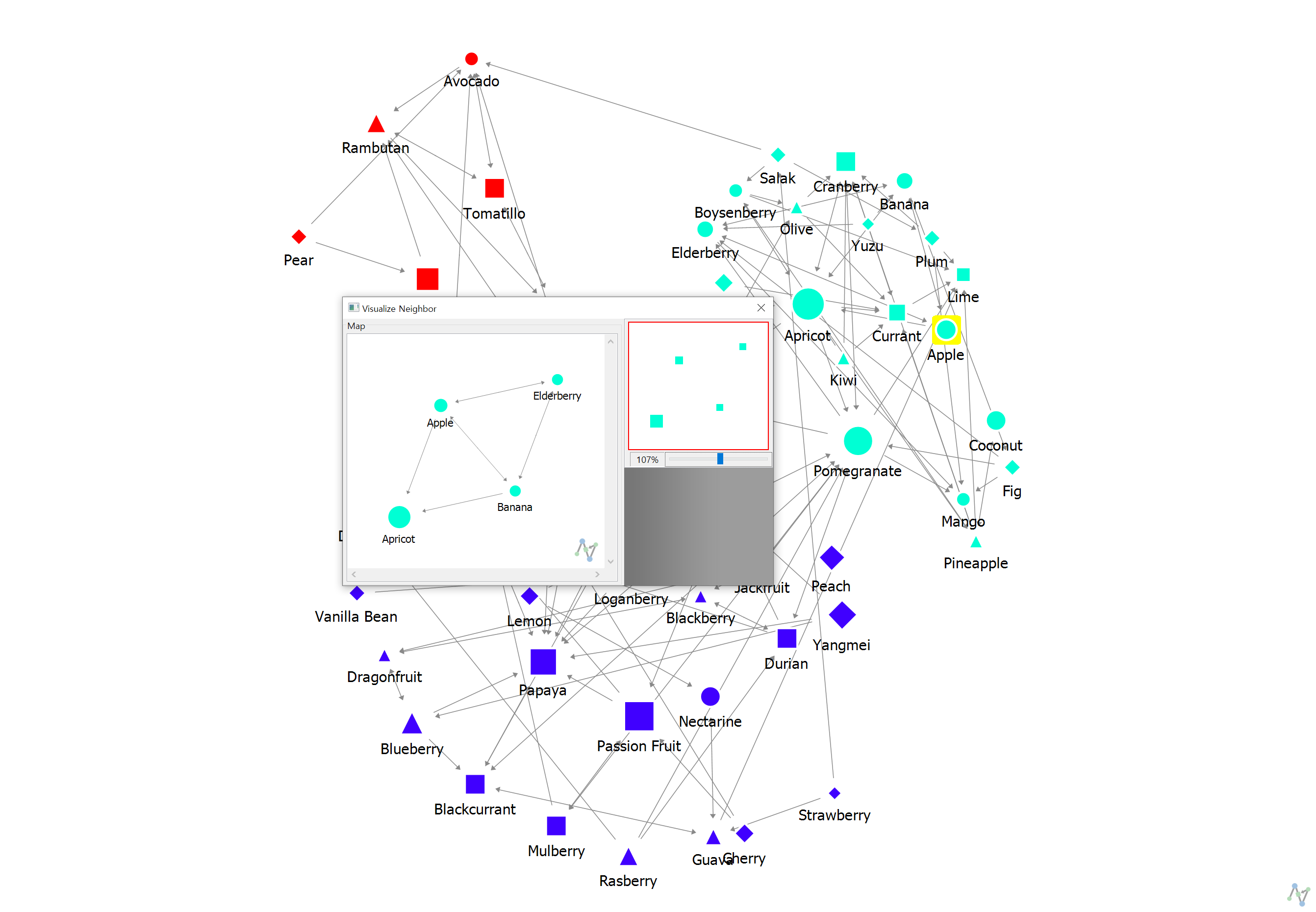
또한 relationship으로 보아도 마케팅 그룹 외 링크가 없는 것 역시 확인이 가능했습니다. 물론 각각의 질문에 대해 최대 링크를 3명으로 제한했기 때문에 해석에는 한계가 있을 수 있지만, 대략적으로 PR Manager가 전체 구성원을 대상으로 소식을 수집하지 못하고 리더의 의견에 따라 콘텐츠를 생산하고 있다는 가설 설정을 해볼 수 있었습니다.
이에 따라 Apple과 인터뷰를 실시하였고 실제로 구성원과 만나 이야기하기 어려운 제약이 있는 것을 확인하였습니다. 이에 Apple에게는 별도 예산을 부여해서 구성원과 돌아가며 맛있는 점심 식사(별도의 점심 식대를 많이 지급했습니다)를 할 수 있게 하고 거기에서 나온 이야기들로 PR 콘텐츠를 만들 수 있게 조치하였습니다.
지금까지 어떠셨나요? 간단한 설문으로도 생각보다 재미있게 인사이트를 찾을 수 있어 저는 이 작업을 하는 동안 상당히 재미가 있었습니다. 물론 저도 넷마이너 초보이기 때문에 넷마이너를 완전히 다 활용하지는 못했다고 생각하고, 더 다양한 방면으로 활용할 수 있는 방법이 많을 것 같습니다.
마지막으로 본 포스팅에서 다룬 넷파이너 예제 파일과 가이드북을 첨부하며 Jarvinspire의 첫 프리미엄 포스팅을 마치겠습니다. 감사합니다. 더 많이 배우겠습니다.